記事公開日
GPUを使おうとしたらCPUが高速化?
F#で行列計算をしよう #7

はじめに
Microsoft F#は、Microsoft .NETグループの一言語であり、.NETで唯一の関数型言語です。関数型言語は副作用が少なく、その結果、完成したコードのエラーが少ないというメリットがありますが、それ以外にもう一つメリットがあります。それは、関数型言語は「行列計算を駆使したDeep Learning系AI処理を書きやすい」ということです。
しかし、F#で行列計算をしようと思っても、Microsoftの公式リファレンス程度しか見当たらず、しかも、それすらまともな解説も使用例もないため、折角の高機能が活かされていません。調べても誰も書いている様子がありません。仕方なく私が作るしかないと考え、F#で行列の計算をする方法を何回かに分けた連載という形でお伝えしようと思います。
真面目に最初から読むというよりは、F#を調べているときに検索に引っかかれば良い、という程度の記事にしていくつもりです。なぜなら、このようなニッチな内容は、AIでは「正しいか正しくないか」の判断が難しいことが多いため、このような記事もあれば、誰かの役に立つのではないかと考えています。
ちなみに、AIそのものの作成方法(誤差逆伝播法など)や、行列計算そのものの意味(意味や計算方法など)、そういったものの説明はしません。そもそも、そのような大層な内容ではなく、あくまで「プログラミング中に困って検索したら引っかかる」ことを目的としています。
前回は、F#が得意とする非同期・マルチスレッドを使用してCPUの使用率を上げて効率良く使う方法を考えてきましたが、結局C言語で書かれたPython用計算ライブラリであるNumpy(DotNet)を使うのが最速であるという結論が出ました。現状ではこれ以上の高速化は難しいと考え、今度はGPUを使って計算速度を上げることを考えます。
前回のちょっとしたおさらいと今回の方針
F#を含めた.NET言語は、一般に「高級言語」と呼ばれる、人間にとってはわかりやすい(補助が多い)言語であるものの、オーバーヘッドが大きく実行速度が速くありません。AI開発でよく使われるPythonも.NETと同じように高級言語であり、しかも実行ファイルを作らないスクリプト言語でもあるため、非常に実行速度が遅い言語と呼ばれています。しかし、それでもPythonが使われるのは「ライブラリ」と呼ばれる後から加える”プラグインタイプ”の関数が強力であるからです。その中でも「Numpy」というライブラリは、AIに必須の行列計算を含む数学的な計算を非常に高速に行うライブラリで、広く使われています。前回の連載では、F#の標準関数だけを使い行列計算するよりも、そのNumpyをF#でも使えるようにする"Numpy.NET"と言われるライブラリを使って行列計算をする方が圧倒的に高速である、という結論を得ました。
ただ、F#にしても、NumpyにしてもどちらもCPUだけしか使っていません。実は、行列の内積計算のような並列に行う事ができる単純計算はGPUが最も得意とするところで、GPUはCPUに比べて圧倒的に高速に計算できると言われています。それ故、現在のAIは、ディープラーニングからOpenAIやGeminiのようなLLMまで、ほぼ全てGPUを使って実行されています。しかし、残念ながら、F#(というか.NET)には、単純な計算をGPUに実行させる機能がありません※1。ですから、今回は、外部のライブラリを使用して、F#を使ったGPU計算に挑戦してみます。
TorchSharp
先ほども書いたとおり、F#単体ではGPUを使った計算は出来ないので、外部のライブラリ(API)を使用する必要があります。候補となるライブラリはいくつかあります。最も一般的なのは、Windows ML (旧Direct ML)です。ただし、Windows MLはかなり基本的なライブラリ(根底にあるライブラリ)であるため、これを使って行列の内積計算をゼロから実装するのはかなり手間がかかります。ですから、今回は様々な機能を持ち、内積計算関数もあらかじめ用意されているTorchSharpというライブラリを使用します。
「Torch」とは、ディープラーニング向けに作られたライブラリです。これを使えば機会学習やそれに伴う計算を少ないコード実行出来るようになります。その中でもPython向けのPyTorchというライブラリはとても有名です。Meta(Facebook)によって開発されたこのライブラリは、様々な計算を並列に計算するよう設計されていて、しかもそれをGPUで実行する機能を持つため非常に高速で動きます。そのためChatGPTやTesla Autopilot等多くのAIでPyTorchが使用されています。
そして、このPytorchの.NET版がTorchSharpです。TorchShrapはGPUで計算する機能を持ちます。ただし、Windows MLが様々なGPUに対応しているのに対して、TorchSharpはNVIDIA製のGPUにしか対応していません。すなわちCUDAのみ対応です。
CUDAとは、NVIDIAのGPU向けにNVIDIAが開発したプラットフォームで、従来グラフィック向けにしか使われなかったGPUを汎用計算にも使えるようにするためものです。かつてはGPUでCPUみないなことをすることからGPGPUと呼ばれていましたが、今現在CUDAというとAIをGPU上で動かすためのプラットフォームを指すことがほとんどで、AIには無くてはならないものとなっています。しかし、CUDAはNIVIAによるNVIDIAのためのものであるため、AMDのGPU(Radeon等)やIntel、AMDのCPUに内蔵されるGPUでは使うことが出来ません。それなのに、AI開発では有無を言わさぬスタンダードとなっているため、AIをGPUで動かそうとするのであればNVIDIAのGPUが事実上必須になります。つまり、CUDAはNVIDIAにとって「囲い込み」の役割を果たすツールでもあるわけです。
というわけで、TorchSharpを使ってGPUの実験をしようとすると、ノートパソコンでは難しくNVIDIAのGPUを積んだPCが必要となります。そのため、今回はいつものノートパソコンではなく社内の実験用デスクトップパソコンを使用してこの実験を行います。
実験に使用したPCのスペックは以下の通りです。
実行環境
- CPU: AMD Ryzen 7 7700X
- 基本 4.50GHz
- 8コア16スレッド
- メインメモリ: 32GB
- GPU: NVIDIA GEFORCE RTX 5060 Ti
- VRAM:16GB

実験に使用したRTX 5060 Ti搭載グラボ(ASUS製)
コスパの良い5060Tiだが、以前は10万円以下で買えたものが現在は13万円強に値上がっている
TorchSharpのインストールですが、Visual StuidoのNugetから"TorchSharp-cuda-windows"をインストールするだけです。ただし、TorchSharpは巨大でダウンロードサイズが4GBぐらいありますので、インストールに時間がかかりますし、「高速かつ定額のネット環境」で行う事を強くお勧めします。
実験内容
さて、過去の記事を踏襲し、引き続き正方行列の「内積の計算」で行列計算の速度を測定していきます。計算のルールは以下の通りです。
- 2つの正方行列の内積(ドット積)を計算する
- 行列のサイズと計算回数を変えて、計算にかかる時間を計測する
- 行列の要素はfloat(double)で、各要素にはランダム値が入っている
計算アルゴリズムは5パターン準備しましたが、時間の関係上、(遅いのが分かりきっている)1と2は行列サイズが512x512より小さい場合のみ使用します。また、1から3の詳しい計算方法・アルゴリズムは過去の記事を参照してください。
- F#で普通に各要素毎に計算する
- F#のスライス機能とMap関数を使って計算する
- Numpy.NETを使用して計算する
- TorchSharpを使用して、CPUで計算する
- TorchSharpを使用して、GPUで計算する
4,5の内積計算のコードは以下の通り。ほとんどGemini Proに聞いたとおりのコードです。途中のdeviceにCPUを設定するかGPUを設定するかで、使用するデバイスが変化します。
| /// 内積サンプル4 /// TorchSharp (GPUによるテンソル計算) let dotTest4 (ary1:double[,]) (ary2:double[,]) = let rows1 = Array2D.length1 ary1 let cols1 = Array2D.length2 ary1 let rows2 = Array2D.length1 ary2 let cols2 = Array2D.length2 ary2 // 1. F#の2次元配列を1次元に平坦化 (TorchSharpへの入力用) let flatAry1 = Array.init (rows1 * cols1) (fun i -> ary1[i / cols1, i % cols1]) let flatAry2 = Array.init (rows2 * cols2) (fun i -> ary2[i / cols2, i % cols2]) // 2. テンソルの作成 (C++側のメモリを使うため use で宣言して自動破棄) // F#の型推論エラーを避けるため、1次元で作ってから reshape で2次元に変形します use t1_flat = torch.tensor(flatAry1) use t1 = t1_flat.reshape(int64 rows1, int64 cols1) use t2_flat = torch.tensor(flatAry2) use t2 = t2_flat.reshape(int64 rows2, int64 cols2) // 3. テンソルをGPUメモリへ転送 // deviceは事前に"torch.CPU"か"torch.CUDA"のどちらかを選択しておく use t1_gpu = t1.``to``(device) use t2_gpu = t2.``to``(device) // 4. 内積計算 (行列乗算)を実行 use ans_gpu = t1_gpu.matmul(t2_gpu) // 5. 計算結果をGPUからCPU(メインメモリ)へ戻す use ans_cpu = ans_gpu.cpu() // 6. 1次元配列としてデータを取り出し、F#の2次元配列へ再構築して返す let ans1D = ans_cpu.data<double>().ToArray() let ansAry = Array2D.create rows1 cols2 0.0 for i in [0 .. rows1 - 1] do for j in [0 .. cols2 - 1] do ansAry[i, j] <- ans1D[i * cols2 + j] ansAry // 戻り値 |
(1から3のコードは過去の記事を参照してください。)
実験結果 1
実験結果は以下の通りとなりました。
表1: 各計算方式における処理時間
| サイズ | 回数 | 1.標準 | 2.スライス | 3.Numpy | 4.TorchCPU | 5.TorchGPU |
|---|---|---|---|---|---|---|
| 64x64 | 10000回 | 23.4 | 21.1 | 5.4 | 1.3 | 2.1 |
| 256x256 | 200回 | 30.7 | 25.9 | 2.5 | 0.8 | 0.5 |
| 512x512 | 200回 | - | - | 20.2 | 2.3 | 2.2 |
| 1024x1024 | 100回 | - | - | 67.8 | 4.1 | 3.9 |
| 2048x2048 | 25回 | - | - | 185.3 | 4.3 | 4.2 |
| 4096x4096 | 3回 | - | - | 191.9 | 2.3 | 2.5 |
単位[秒]
Torch速い!圧倒的に速い!が・・・ CPUとGPU大して変わらない。つまり、この結果はTorchの行列計算が圧倒的に高速であるという事を意味するだけで、GPUが速いことは証明していない。どうなってるの?
そして、当然ここで疑問に思うわけです。効率が良いといえども、GPUはともかくCPUでこれほどまで速くなるものなのか? NumpyだってC言語で書かれていて高速と言われているし、NumpyのCPUの使用率だって30%近くあるため、良くて精々3~4倍程度なのでは?とか。
もしかしたら、なんかミスしていて計算結果が正しくないのかも?と思って確認してみました。すると、つまりF#またはNumpyで計算した値と、TorchSharpで計算した値が微妙に違うんです。F#やNumpyで計算すると小数点の末端までまったく同一値となるのですが、TorchSharpだと本当に微妙に違う。例えば、これぐらい違うんです。
- Numpyで計算した値: 5.7740040177038194
- Torchで計算した値: 5.7740040177038185
小数点15の桁ぐらいで差がある。かなり微妙な差。しかも、これ全ての値で違いが出るって訳でもない。ざっくりカウントしたところおおよそ1/4ぐらいの確率で上記のような差が出るんです。もしかしたら、Torchが使う計算のアルゴリズムが他と若干違い、高速化を優先し精密さを捨てているかもしれない。
それで調べてみると、「oneMKL/AOCL」や「AVX-512」という単語が出てきます。どうやら、こいつらがCPUの処理の高速化を担っているようです。
oneMKLのMKLはMath Kernel Libraryの略で、インテルが開発したCPUで高速に算術計算をするためのライブラリとのこと。oneMKLは優れた機能を持つもののIntel CPUにしか対応していないため、(Intelのライバルである)AMD CPUでは使えません。そのため、AMDが別途AOCL(AMD Optimizing CPU Libraries)というAMD CPU向けの算術計算用ライブラリを開発しています。これらは大体同じような技術であり、どちらもTorchSharpの大本であるTorchのライブラリ(LibTorch)に採用されているため、TorchSharpでも使えるようです※2。
また、APTX-4896※3に似た名前のAVX-512は、もちろんCPUを小さくする薬ではなく、12ビットのデータ幅を一度に処理できるIntel/AMDのCPU向けの命令セットのことで、これによりCPUでもGPUのように高速に並列計算できるようになる、というものです。ただし、高速であるものの、その代償として発熱が大きくなるため、発熱に悩む最近のIntel CPUでは採用されておらず、現在はAMDのデスクトップ用CPUにのみ搭載されているようです。今回の実験に使っているCPUはAMDのRyzen 7 7700Xなので、AVX-512が使えます。
恐らくですが、これらの2つの技術がTorchSharpをCPUで使っても高速に行列計算ができる理由であるとともに、計算に誤差が出る理由ではないかと考えられます。そのため、AOCLとAVX-512の効果を確認すべく、AVX-512に対応していないCPUと比較することにしました。
私が普段使っている仕事用のノートがAMDのCPUで、こちらはAOCLには対応していますが(ノートPC用CPUのため)AVX-512には対応していません。Numpyは調べた限りAVX-512に対応しているようです。そのため、TorchSharpによるAOCLの効果は実験用PC、ノートPCの両者に出て、AVX-512の効果は実験用PCにのみ出るはずです。ですから、実験用PCと私のPCで、Numpyの処理時間とTorchSharpのCPUの処理時間を比較することで、AOCLとAVX-512の効果が確認できるはずです。
尚、ノートPCのスペックは以下の通り
- CPU: AMD Ryzen 7 Pro 250
- 基本 3.30GHz
- 8コア16スレッド
- メインメモリ: 32GB
というわけで、両社を比較した実験結果が以下です。 表2: CPUの違いにおける処理時間の違い
| 実験用PC(Ryzen 7 7700X) AOCL+AVX-512 | ノートPC(Ryzen 7 Pro 250) AOCL Only | - | ||||||
|---|---|---|---|---|---|---|---|---|
| サイズ | 回数 | 3.Numpy | 4.TorchCPU | 倍率 | 3.Numpy | 4.TorchCPU | 倍率 | AVX効果 |
| 512x512 | 200回 | 20.2 | 2.3 | 8.78 | 41.2 | 3.9 | 10.56 | +16.9% |
| 1024x1024 | 100回 | 67.8 | 4.1 | 16.54 | 178.6 | 7.5 | 23.81 | +30.6% |
| 2048x2048 | 25回 | 185.3 | 4.3 | 43.09 | 872.1 | 11.9 | 73.29 | +41.2% |
| 4096x4096 | 3回 | 191.9 | 2.3 | 83.43 | 883.9 | 6.7 | 131.93 | +36.8% |
| 平均 | - | - | - | - | - | 59.90 | +31.3% | |
実験用のPCはNumpyがAVX-512のみ効果、TorchSharp-CPUは、AOCL+AVX-512の効果となります。一方ノートPCの方はNumpyは効果無し、TorchSharp-CPUはAOCLの効果のみとなります。したがって、まずノートPCの時間短縮率を見れば、AOCL(TorchSharpの効率含む)の効果が分かることになります。そして、実験用PCの効果からノートPCの効果を排除するとAVX-512の効果が分かるはず、そういった算段です。
上記考えによると、AOCLによる効果は平均速度が59.9倍になり、AVX-512による効果は平均で+31.3%高速となります。つまり、AOCLは使わないときに比べ60分の1にまで時間を短縮でき、AVX-512は使わないCPUと比べ30%近く時間を短縮できる、そういったことになります。この結果が正しいかどうかは別として、この計算結果はどちらももの凄く効果があるという事を表しています。ただし、その代償として少々の誤差の発生ということになるようです。
実験結果 2
しかし、今回私が調べたかったのはGPUの効き目です。CPUの速さではありません。先ほどの実験結果1で、なんでCPUとGPUの差が無いのか詳しく調べてみると、なんとGPUは「float32(single:32bit単精度浮動小数点数)に特化しており、それを使った計算が最も速くなる」と書いてあります。これまで一番計算に時間がかかるfloat(double:64bit倍精度浮動小数点数)で計算していましたが、確かにAIもグラフィックもそこまでの制度を必要としない計算です。これまでdoubleで計算していたため、GPUの性能を十分に発揮できていなかった可能性があります。
したがって、次はGPUの効果を見るためコードをざっくり直して、single対応に変更して計算してみます。といっても、F#では引数の型を変えたり、リテラル数(直接の数値)を10.0みたいな表記から10.0fに変えるだけなんで、簡単なんですけどね。で、このsingle対応コードでCPUとGPUの差を調べてみます。
表3: doubleとsingleの処理時間の比較
| サイズ | 回数 | 1.標準 | 2.スライス | 3.Numpy | 4.TorchCPU | 5.TorchGPU | |
|---|---|---|---|---|---|---|---|
| 64x64 | 10000回 | double | 23.4 | 21.1 | 5.4 | 1.3 | 2.1 |
| single | 29.9 | 25.3 | 2.3 | 0.6 | 0.4 | ||
| 256x256 | 200回 | double | 30.7 | 25.9 | 2.5 | 0.8 | 0.5 |
| single | 29.9 | 25.3 | 2.3 | 0.6 | 0.4 | ||
| 512x512 | 200回 | double | - | - | 20.2 | 2.3 | 2.2 |
| single | - | - | 13.1 | 1.6 | 1.4 | ||
| 1024x1024 | 100回 | double | - | - | 67.8 | 4.1 | 3.9 |
| single | - | - | 67.4 | 3.7 | 3.1 | ||
| 2048x2048 | 25回 | double | - | - | 185.3 | 4.3 | 4.2 |
| single | - | - | 166.8 | 3.4 | 2.6 | ||
| 4096x4096 | 3回 | double | - | - | 191.9 | 2.3 | 2.5 |
| single | - | - | 197.9 | 1.7 | 1.3 | ||
単位[秒]
double(double)からsingle(float32)への変更は、一要素のデータが半分になるので、計算量的にも半分になるように思うのですが、少なくとも”1.標準”から"3.Numpy"までは結果を見る限り大きな差は無いように見えます。また、本題のTorchSharpにおいてはCPUにしてもGPUにしても、結果の時間が短すぎて誤差が大きい可能性が高いです。そのため、実験をTorchSharpに絞り、もう少しサイズの大きい行列で、かつ計算回数を増やすように変更して再度行ってみました。
表4: doubleとsingleの処理時間の比較2
| サイズ | 回数 | 4.TorchCPU | 5.TorchGPU | |
|---|---|---|---|---|
| 4096x4096 | 50回 | double | 36.9 | 40.6 |
| single | 28.5 | 20.9 | ||
| 5120x5120 | 50回 | double | 63.1 | 72.1 |
| single | 47.7 | 33.2 | ||
| 6144x6144 | 50回 | double | 98.3 | 118.0 |
| single | 71.3 | 46.4 | ||
| 7168x7168 | 50回 | double | 144.8 | 173.2 |
| single | 102.6 | 62.2 | ||
| 8192*8192 | 50回 | double | 200.1 | 241.9 |
| single | 139.1 | 82.3 | ||
やっと、GPUの時間が短くなったように見えますね。で、この実験の結果をよく見てみると、以下の様なことが分かります。
- doubleの時は、GPUよりCPU(AOCL+AVX-512)の方が高速
- singleの時は、CPUよりGPUの方が高速
- GPUはCPUの6割程度の時間で終了している
- GPUの使用率は、doubleの時は100%近い使用率になっているのに比べ、singleの時は6~7%程度にしか上がらない
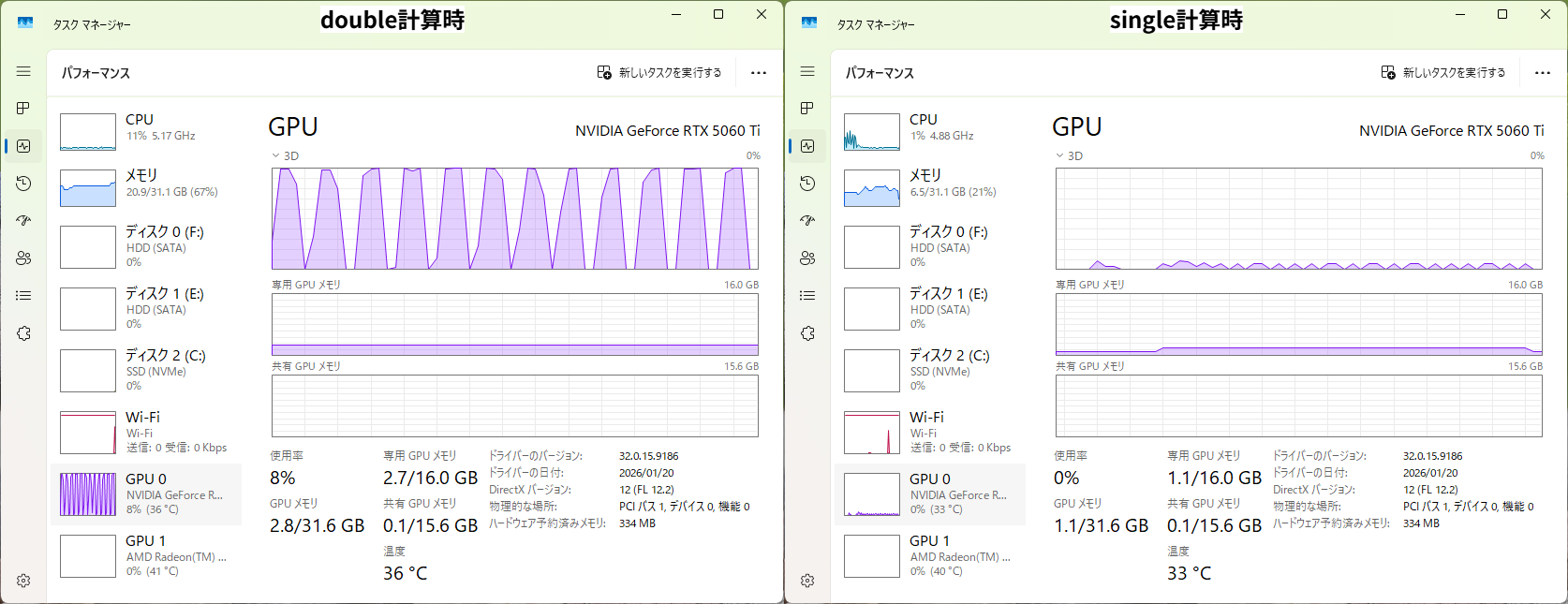
doubleとsingleのGPU使用率の違い
上記の実験結果だけを見れば、GPUはsingleの方が高速に動くのは間違いないものの、それでもCPUとの差は期待より大きくない、と言えます・・・ 何故だ?
なぜGPUが期待外れなのか?
というわけで、なぜGPUが期待外れなのか理由を調べてみました。
まず、GPUに向いていないdoubleの計算では100%のGPU使用率になるのに、singleは最大でも10%に届きません。それなのに、doubleの計算はCPUより遅く、singleはCPUより高速だったという点。この理由は、GPUのスペック表をみると分かるようです。GPU(GeForce RTX 5060Ti)のスペック表には以下の様な項目がありました。
- FP32 (single) 23.70 TFLOPS
- FP64 (double) 370.4 GFLOPS
これは、GPUが理論上1秒間に何回計算できるかを表す"FLOPS"の値です。これを見るとFP32、つまりsingleの場合は23.70テラ回(23.7兆回)計算できるのに対して、doubleの場合は370.4ギガ回(3704億回)しか計算できません。doubleはsingleの丁度64分の1ですが、これはそもそもハートウエア的にdouble用の計算ユニットがsingle用の計算ユニットの64分の1しか搭載されていないことを意味します。つまり、GPU(GeForce RTX 5060Ti)はdoubleを計算するユニットが少ないため、その少ないユニットを占有したとしても計算速度は上がらない、というわけです。この計算ユニットの数や割合はGPUによって異なるため全てのGPUにおいてdoubleの計算が遅いというわけではないのですが、GPU本来の用途であるコンピューターグラフィックスとAI計算において主に使うのはsingleであることから、GPUはsingleの方が速くなるように設計されることがほとんどです。
ただし、計算ユニット数だけで実際の計算時間が決まるわけではありません。今回の結果を見ても、GPUの計算能力が64分の1だからといって、計算時間は64倍になっていないどころか、2倍にすらなっていないですよね?この原因は、どうやらメモリにあるようです。
一般的なコンピューターには、汎用のメインメモリ(RAM)と、GPUが専用で使うビデオメモリ(VRAM)の2つが搭載されています※4。RAMにはOSやアプリなど様々なものが読み込まれます。通常用途で使われるのはほとんどRAMです。CPUはRAMを頻繁に見に行くので、CPUのそばに配置されます。一方のVRAMは、GPUと太いバスで接続されているもののGPUを使うゲームやAIを起動しない限りほぼ使われません。それにもかかわらずVRAMはRAMより10倍近く高速なメモリが使われています。高速=高価ですから潤沢に載せることはできません。例えば、グラフィックボードを搭載していないノートPCやビジネスPCでは、RAMは16GBや32GBが当たり前であっても、VRAMはCPU内蔵GPUのためにお情け程度(512MB~1GB)しか搭載されていません。
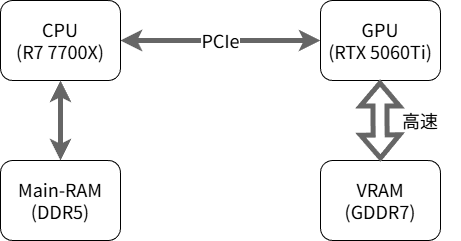
メモリのブロック図
今回の行列計算は、4096x4096等の巨大な行列を使用しました。この4096x4096の行列は要素がsingle(32bit=4byte)の場合、その行列1つだけで67MBものサイズとなります。このような巨大なデータの場合、GPUはメモリから数値を出し入れしながら計算を行うことになります。
GPUは高速なVRAMを使うことで真の能力を発揮することが出来ます。ですから、ゲームやAIの場合はVRAMの容量により速度や品質が左右されます。しかし、今回の実験では計算に使うデータはほとんどRAMに配置されたようです。というか、普通の数値計算はRAMに配置されるのが当たり前です。そして、GPUからRAMは遠いため、そのアクセス速度はあまり速いとは言えません。そのため、GPUによるsingleの計算も能力が完全に発揮できなかったと考えられます。GPUの使用率から見れば、おそらくはその性能の10%も使用できていなかったのでしょう。
残念ながら、F#にもTorchSharpにも、計算のためのリソースをRAMとVRAMのどちらに配置するかまで決定する命令は存在しません。本来、データをVRAMに載せて試せたら良かったのでしょうけど、それは今後の課題とし、この連載は以上とさせて頂きます。
まとめ
「F#で行列計算をしよう」ということで7回にわたり連載してきました。これまでの連載でF#のコードを工夫したり非同期計算をやったりと、ぐだぐだとやってきましたが、結論はF#上でどんな工夫もしようとも、TorchSharpに比べれば誤差でしかないということになります。やはり、所詮高級言語で何を書こうとも、CPUやGPUのハードウエア的支援を受ける以上の速度を出すことは出来ないってことです。そして、これを逆に考えれば「どんな言語で書こうともTorchSharpのようなライブラリを使えば高速に動かせる」ということでもあり、言語なんて関係無いということでもあります。であれば、F#のエラーが見つかりやすく、結果的に早く書けるアドバンテージが認められれば、AI向け言語として生き残るチャンスはあるということです。(我田引水のこじつけじゃないですよ!)
というわけで、行列計算の連載は終わりますが、引き続きF#の布教活動の一環として、F#を取り上げていきますので、引き続きよろしくお願いします
※1; WPF以降の.NETは、UIの表示(グラフィック表示)で自動的にGPUを使う様になっているが、明示的にGPUを呼び出し計算させるような標準関数は存在しない。また、行列計算のような非グラフィックス計算を自動的にGPUへ割り振る機能もない。
※2; oneMKLやAOCLに対応したNumpyも存在するため、それを使って計算すればTorchSharpと同等の計算速度だった可能性がある。
※3; APTX-4896(アポトキシンよんはちろくきゅう)は、青山剛昌作の漫画「名探偵コナン」に出てくる架空の毒薬で、この薬を飲むと頭脳はそのままで体が子供になる。「名探偵コナン」は高校生探偵「工藤新一」がこの薬を飲まされて子供の体になってしまったが、「江戸川コナン」を名乗り活躍するという設定である。
※4; RAMとVRAMが分かれていないコンピューターもある。例えばApple Mac(ARM)やゲーム機であるPlaystation 5は、高速のメモリをCPUとGPUで共用する「ユニファイドメモリ」方式を採用している。