

LED通信事業プロジェクト エンジニアブログ
F#で行列計算をしよう #3
二次元配列を一次元にする 前編
記事更新日 2024年11月19日
はじめに
Microsoft F#というのは、Microsoft .NETグループの一言語ですが、.NET唯一の関数型言語です。関数型言語は副作用が少なく、その結果完成したコードにエラーが少ないというメリットがあるのですが、それ以外にもう一つメリットがあります。それは、関数型言語は「行列計算を駆使したDeep Learning系AI処理を書きやすい」というものです。
ですが、何とF#で行列計算をしようと思っても、Microsoftの公式のリファレンスぐらいしか出ておらず、しかも、それすらもろくな解説も使用例もなく、折角の高機能が台無しです。調べても誰も書いている気配が無い。仕方ないので私が作るしか無い、ということでF#で行列の計算をする方法を何回かに分けた連載という形でお伝えしようかと思います。
真面目に頭から読む、というよりはF#を調べているときに検索に引っかかったらよいですね、ぐらいの記事にしていくつもりです。というのも、こういうレアな内容って、AIだと"正しいか正しくないか"がわかりにくいことが多いので、こんな記事もあればあるで誰かの役には立つんじゃないかと思っています。
ちなみに、AIそのものの作成方法(誤差逆伝搬法とか)や、行列計算そのものの意味(内積・外積の意味とか計算方法とか)とか、そういったものの説明はしません。そもそも、そんな大層な内容ではございませんで、あくまで「プログラミング中に困って検索したら引っかかる」ことを目的としています。
今回は、3回目で2次元配列から1次元配列へ変換するという話題です。正直、F#の記事って、アクセス数も検索数も低いんで、(会社の都合上)記事に登場する頻度はとっても低くなってしまうのですが、趣味のページとして残していきたいと思ってます。
尚、前回の記事はこちらになります。
2次元配列にない関数
前回も書きましたが、F#には、行列(配列)を計算するための便利な関数が沢山あります。ただし、2次元以上の配列に存在する関数と、1次元配列に存在する関数では、その数が違います。圧倒的に1次元配列の関数が多いのです。例えば、配列に同じ解散を施すmap関数は、2次元以上の配列にもありますが、2つの配列同士で計算させるmap2関数は1次元配列にしか存在しません。それ以外にも、挙げていればキリが無いほどの違いがあります。ただ、AI系をやるなら、2次元以上の配列が基本ですし、どうにか1次元にしかない関数を2次元で使えないものでしょうか?
1次元配列にしか関数が無いのなら、2次元配列も1次元配列にしてしまえば良いのでは?
そうだ!2次元配列の形だけ記録しておいて、一旦2次元配列を1次元配列に直して、関数で計算する。そして、それを2次元配列へ戻せば高速に処理できるのではないか?うん、出来るはず。しかし、2次元配列をどうやって1次元配列に変換したら効果的なのかな? 何か、良い方法は無いのか?
ということで、今回は「2次元配列を1次元配列にする」というテーマでやっていきたいと思います。
Pythonとは違うのだよ(涙)
最初に、いきなりPython(パイソンと読みます)の話をします。正直、AI関係の計算で最も使われる言語はPythonです。これは、もう異論が出ないほどの事実です。で、Pythonに人気があろうがなかろうが(この記事では)どうでも良いんですが、Pythonの配列(行列)って、何次元であっても「内部計算上はすべて1次元」なんですよね。だから、1次元の配列を2次元にするのも、その逆をするのも、ほぼノーコストで変換できます※1。というか、内部的には1次元の配列に、2次元のガワを被せているってだけなんで、ガワを変えるだけですからね。AIでは、配列の次元を変えるという計算もよくするので、そういう面でもPythonって便利なんですよね。だから、仮に1次元配列にしか適応できない関数があったとしても、Pythonではさほど問題にはなりません。
けどね、F#はそんな甘くありません。なにしろ、F#はもの凄く型に厳密な言語だから。配列も1次元と2次元は、全く別の型になるため、そう簡単には変換させてくれません。すくなくとも、何も考えずに一発で変換できるような関数は存在しません。だから、F#ユーザーは自分で考えて、配列の次元を変換する関数を作らなくてはいけません。ふふふ、F#は、そう簡単に型変換はさせないのだよ!
配列の次元を変えるやり方は、いくつか思いつくと思いますが、どのようにやったら最も効率的なのか、実は私にも分かりません。ということで、いろいろと変換を試してみることにしました。
前準備
いろいろと試す前に、前回でも使った「要素が乱数の2次元配列」を準備したいので、次のような関数を作ってみました。気休めかも知れませんが、中身が単純な配列だと、中間言語が変な最適化してしまうかも知れませんので。この関数は、今後何度も出てきますが、単に中身0~1のランダム値を持つ二次元配列を作る関数ですので、ご承知置きを。
/// ランダム要素の配列を作成する関数
let createRandomArray2D y x =
let ary = Array.create 10000 0.0 // ランダム計算するためのダミー配列
let ary2Dtemp = Array2D.create y x 0.0 // ランダム計算するためのダミー配列
let rnd = new System.Random() //乱数の宣言
let mapfunc a = rnd.NextDouble() //MAP関数(乱数を生成)
Array2D.map mapfunc ary2Dtemp //ランダム配列(戻り値)
2次元配列を1次元配列へ変換する方法
ここから、2次元配列を1次元配列へ変換する方法をいくつか紹介します。どの、方法が最も高速に変換できるか試していきます。以下の条件で時間を測定します。
- コピー元の2次元配列は、
createRandomArray2D関数で作った64x64の2次元配列 - それを、長さ4096の1次元配列へ変換
- 変換時間を計測するために、十万回繰り繰り返す
- 計測には.NETのStopWatchクラスを使用(今後のコード例には載せていません)
- さらに、計測を10回繰り返し平均を取る
要素毎に代入する
さて、最初の変換方法です。2次元配列から1次元配列への変換を実施するとして、恐らく誰もが最初に思いつく方法が、for文を作って、2次元配列から1次元配列へ、要素毎に代入するって方法でしょう。コードは長めですが、考え方は単純です。コードとしては、こんな感じです。
// 1要素ずつ代入するコード
let ary2d = createRandomArray2D 64 64 // コピー元の64x64ランダム2次元配列を作成
// 100,000回繰り返す
for count in [1 .. 100000] do
// コピー先の1次元配列を作成
let ary1d = Array.create (64*64) 0.0
// 2次元配列を1次元配列へ変換するコード
// yとxでfor文を入れ子にして、各要素毎に代入する
for x = 0 to 63 do
for y = 0 to 63 do
let i = y * 64 + x
ary1d[i] <- ary2d[y, x] // 代入する
コードは、どんな言語でもあるようなfor文を入れ子にした構造です。配列の各要素へのアクセスは、1次元配列ならexample[x]、2次元配列ならexample2D[y,x]と書きます。かつては、example.[i]と配列名とインデックスの間にドットを入れていましたが、2021年リリースの.NET6(F#6)からドットが不要になりました。ちなみに、配列のインデックスを[x, y]ではなく、[y, x]と書いているのは、F#含む.NETでは、座標表現は縦が先、横が後になっているから。これは、配列だけじゃなく、例えば画面座標の指定でもそうなっています。そして、.NETに限らず、多くの言語でも同じです。
尚、この方法を計測したところ、平均時間は1059.6msでした。これが基準時間で、これより早くなれば、効率の良い方法ってことでしょう。
スライスしてみる
私は、F#がAIに向いていると勝手に書いていますが、その理由の一つが配列の「スライス」だと思います。スライスとは、配列の好きな部分を抽出してくる機能です。下の図のように、配列の好きな場所を指定して抽出し、新たな配列を作り出します。1次元配列の一部だけを抜き出すことも出来ますし、2次元配列の行や列だけを抽出し、1次元配列を作ることも出来ます。まあ、色々出来るんです。
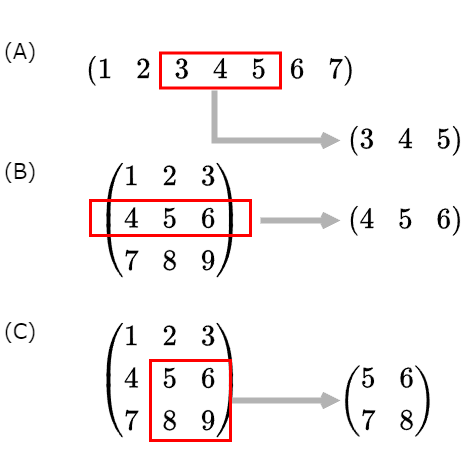
配列のスライス
で、このスライスなんですが、言語によって得意不得意がでます。例えば、.NETの仲間であるC#とVB.netは、特殊な関数を使わないとスライスできないし、制限も多いし、結構面倒です。しかし、F#は、関数いらずで、とっても簡単に配列のスライスできるんです。すごい!F#かっこいい!ここまで簡単な言語もなかなかありませんよ!
F#のスライスは、次のように行います。配列のインデックス[ ]の中に、指定する幅を入れれば良いのです。通常、インデックスって、[5, 2]みたいな、1つの要素を限定して指定するものなんですけど、これを複数指定する形にすれば、スライスになります。例えば、インデックスで[0..9, 3..5]と指定すれば、(インデックスは0スタートなので)1~10行目の4~6列目という、配列を抜き出します。また、行や列がまるまる全部必要ならワイルドカードである*を入れると、「全て取ってくる」となります。つまり、F#においては、特定の1つ要素を指定するために存在すると思っていたインデックス[]は、実は、ある範囲を指定するために存在していたって言えるんですよね。
F#のスライスがどれだけ簡単かは、実際にコードを見て貰うのが早いと思うので、早速上の図の(A)(B)(C)のスライスをF#で実装してみます。
// (A)のスライス
let ary1d = [|1; 2; 3; 4; 5; 6; 7|] //元となる配列
let sliced1d = ary1d[4..6] //5番目から7番目をスライス
//val sliced1d: int array = [|5; 6; 7|]
// 元となる2次元配列で、1~9までの番号を付けた配列を作成(今回は説明を割愛)
let createNum y x = y * 3 + x + 1
let ary2d = Array2D.init 3 3 createNum
// val ary2d: int array2d = [[1; 2; 3]
// [4; 5; 6]
// [7; 8; 9]]
//(B)のスライス
let sliced1d2 = ary2d[1,*] //*を使って、2行目をスライス
//val sliced1d2: int array = [|4; 5; 6|]
//(C)のスライス
let sliced2d = ary2d[1..2,1..2] //上から2~3番目、左から2~3番目をスライス
//val sliced2d: int array2d = [[5; 6]
// [8; 9]]
- 最初に(A)です。1次元配列である
[|1; 2; 3; 4; 5; 6; 7|]から、[|5; 6; 7|]を抽出するには、左から5~7番目の要素を抽出すれば良いのです。だから、インデックスとして4~6を指定すれば良いのです。 - (B)は、3x3の2次元配列の2行目、真ん中の行を抽出しています。その場合、縦のインデックスとして1を指定し、横のインデックスには
*を指定します。*は、ファイル検索とかでもおなじみですが「何でも良い」を意味しますから、配列のインデックスとして[1, *]を指定すれば、2行目の全てを抽出しろという意味となります。 - (C)は、2次元配列の右下を抽出します。上から2~3番目、左から2~3番目をスライスすればよいのですから、インデックスは
[1..2,1..2]となります。
どうですか?本当に簡単でしょ?t特に、C#の人には「めちゃくちゃ便利」と思われるでしょう。やっぱり、.NETで配列を操作したいならF#しかありませんよ、皆さん!ちなみに、このF#のスライスの方式、Pythonに似てるんですよね。この辺もPythonがAIに強い理由でもあります・・・
おっと、前置きが長くなってしまいましたが本題に戻ると、この「簡単にできるスライス」を使って1次元配列を作ろうというのが、この方式の趣旨です。とは言え、スライスを使って2次元配列を1次元配列にできる、それは行なり列なりをスライスした場合のみ。したがって、2次元配列全体を1次元配列にしたい場合、行毎にスライスして、それを繋げるという作業が必要です。それを実現するには、こんなプロシージャとなります。
- 一時コピー先となる1次元配列を要素とする1次元配列を作ります。つまり、配列の配列を作ります。配列の配列は、ジャグ配列とも呼ばれます。
- 各行をスライスしていき、一時コピー先のジャグ配列へ代入していきます。
- 最後に、配列の要素を全部繋げて、単純な1次元配列を作ります。
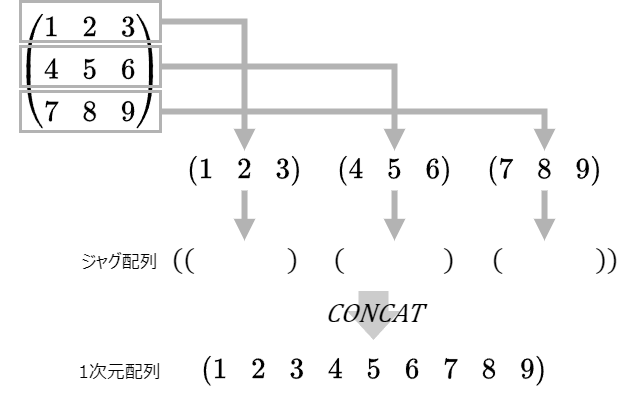
最後、「配列を要素を繋げる」と簡単に書いていますが、これは1次元配列のみに存在する関数concatを使えば可能です。他の言語にもある関数で、配列と配列を結合させます。ここでのconcatの用途は、配列の配列、つまりジャグ配列を、単純に一つの配列にしてしまうってことです。
これを実現するコードは次のようになります。
let ary2d = createRandomArray2D 64 64 //コピー元の64x64配列を作成
//一時代入用に配列を要素に持つ1次元配列を定義
let ary1dary = Array.create 64 (Array.create 64 0.0)
// 100,000回繰り返す
for count in [1 .. 100000] do
// 行毎にスライスして、一時代入用のジャグ配列へ代入
for y = 0 to 63 do
ary1dary[y] <- ary2d[y, *] //行をスライスしてジャグ配列へ代入
let ary1d = Array.concat ary1dary //最後に1次元の単純配列にする
なんか、最初の全要素コピーとあまり変わらないコードですが、行単位でコピーしているので、要素にアクセスしてコピーする回数は列数分の1、つまりこの例では1/64になっているのだから、時間も短縮できているはず。ということで、タイムを計ってみました。その結果は、なんと平均1522.3ms!!。あれ?遅くなっているどころか、全コピーの1.5倍近くかかってる。どういうことだ?concatが遅いのか?と思って、concatを削除して再計測したんですが、それでも平均930msぐらいかかる。つまり、個々の要素にアクセスしたほうが、スライスするより早いってこと?そんなはずはない!
行列のサイズを増やしてみた
ということで、上のコードのコピー元の2次元配列を64x64から256x256に変更して計測してみました(その代わり十万回から一万回に削減)。行列が小さいから、スライスが効果を発揮しないのかも知れません。だったら、配列のサイズを増やせばよいはず。というわけで、行の長さを4倍にして、スライスの効果アップ!! ちょっとコードを直して、計測し直しました。その結果は、以下の通り
256x256配列 10,000ループ
- 要素毎に代入=>平均4627.2ms
- スライスしてconcat=>平均4946.6ms
結構と近くなりましたが、まだちょっと遅い。ただ、やはり列数が増えると、スライスの威力が増すようです。じゃあ、更に増やしましょう。
1024x1024配列 200ループ
- 要素毎に代入=>平均6348.2ms
- スライスしてconcat=>平均1340.4ms
やっと、スライスの効果が出たようです。これは、スライスで切り取る要素数が多くなればスライスが効果を発揮してくるってことです。だから、要素毎に代入していくか、スライスを使用するかは、配列のサイズで決める必要がありそうです。
concatじゃなくてappendは?
concatに似ている関数であるappendはどうでしょう?Array.appendという関数は、英語の意味の通り行の後ろに配列を追加するという関数です。concatと似ていますが、concatは全体を合体、appendは都度後ろに追加するっていう意味です。
ただね、これ念のため試しただけなんです。これ、他言語の経験からです。.NETのVB.netには、他の言語にはないRedimという配列の要素数を後から変更の出来る関数があるのですが、これが恐ろしく重くて遅い処理なんです。原理を考えれば当たり前なんですけどね。このRedimは、配列の大きさを広げているように見える関数なんですけど、内部的には、配列を再宣言してメモリを新たに割り当てているですよね。メモリの参照じゃなくって、割り当てですからね。このメモリ割り当てという動作、配列のサイズが小さいうちは良いんですけど、配列のサイズが大きくなればなるほどコストのかかる処理になります。繰り返しやっちゃダメな処理です。for文とかで、要素を追加する毎にRedimを繰り返すコードを書くと、それはそれは時間のかかる処理になります。最初から無駄なぐらい大きな配列を宣言した方が、圧倒的に速い。そう考えると、F#のArray.appendもRedimと同じことをやっているわけだし、同じように遅いんじゃないかと・・・
というわけで、Appendについては、コードすら載せませんが、結果だけ書いておきます。最初の64x64の配列を100,000回ループさせるという方法で時間を計ったところ、平均時間は18140ms。一桁違います。問題にならないほど遅い。おそらく、256x256の配列なんて計算したら、恐ろしく時間がかかって、途中でコードを止めたくなることでしょう。
まとめ
スライスの説明が、思いのほか長くなってしまいましたので、2回に分けてお送りすることになりました。いや、スライス自体は、めちゃくちゃ便利なので、.NETが好きなのに、スライスの弱さでPythonを使わざるを得なかった人は、是非F#にチャレンジしてみてください。
次週も、引き続き2次元配列を1次元配列へ変換するのに、もっと良い方法は無いのか?探っていきたいと思います。
※1; PythonでAIを扱う場合は、通常、追加モジュール(ライブラリ)である"NumPy"を使用する。配列も、NumPyの機能を使用して宣言することが一般的なため、配列に関する操作も、厳密に言えばPythonの機能ではなくNumPyの機能である。