

LED通信事業プロジェクト エンジニアブログ
Bluetooth LE Audioってなに? その1
高校生でもわかる通信用語 #21
記事更新日 2025年7月1日
はじめに
理系高校生や文系大学生でも分かるように通信用語を説明する「高校生でも分かる通信用語」の第21回です。今回のテーマの方は「Bluetooth LE Audioってなに?」です。
Bluetoothといえば、皆さんもご存じの通り、機器と機器を繋げるための無線規格です。同じ2.4GHzを使うWi-Fiが、できるだけ高速に通信することを狙っている技術なのに対して、機器を繋げるのに特化したBluetoothは、省電力に通信することを重視した技術と言えると思います。
もともとBluetoothは、パソコンとマウス、キーボードを接続する、または携帯電話とヘッドセット(通話用のイヤホンとマイクのセット)を接続する目的で使われていました。さらに、BluetoothはWi-Fiのようにデータを通信することも出来ます。ただし、通信速度は速くないために、今も昔もその機能はあまり使われていません※1。
さて、今回の話はBluetoothの最新オーディオ規格である、Bluetooth LE Audioの話です。最近のスマホは、有線ヘッドホンを挿すための穴(ジャック)が空いていない機種も多くて、スマホの音を聞きたきゃBluetoothのヘッドホンを買えと言わんばかりです。そのため、これを読んでいる皆様のほとんどが、Bluetoothのヘッドホンを使っているんじゃないでしょうか?
でも、そのヘッドホンがBluetoothで繋がっていることは知っていても、実際にどのような技術によって接続されているかを知っている人は、多くないと思います。そりゃそうです。Bluetoothはもともと対応機能がわかりにくい上に、各メーカーはその対応状況を小さくしか書いていないため、ユーザーに理解させる気はありません。その上、Appleが左右独立のAirPodsを発売して以降、Bluetooth接続の物理的な方法が多種多様になり、さらにユーザーには見えにくくなっています。そもそも、Appleを筆頭にメーカーが情報を公開していないことも多く、普通の人だと知る機会すらありません。
というわけで、今回はBluetoothがどのようなものから説明を始めて、なぜBluetooth LE Audioが生まれたのか、そして、今後どのような用途で使われる可能性があるのかを、通信の面を中心に説明したいと思います。4回にもわたる長編で、しかも一部はかなり突っ込んだ内容となりますが、技術的にはそこまで難しい話ではないので、頑張って読んで貰えると普段使っているBluetoothイヤホンに対する理解が深まると思います。
尚、コーデック(音声圧縮方式)の話にも多少は触れますが、そのコーディング理論とか、音質の善し悪しとかには触れません。このブログは「通信用語」がテーマですので、基本は通信や接続に関する話になりますので、ご承知置きを。
Bluetoothと周波数ホッピング
最初はBluetoothの基本から入ります。
Bluetoothは、もともとPCとキーボードやらマウスやらの無線接続、また携帯電話とPCや情報端末(PDA)がデータ通信するための無線接続として生まれたものです。キーボードやマウスの接続であれば、通信の速度は必要とされません。また、携帯電話とPCの通信用の接続にも使われていましたが、Bluetoothが生まれた当時の携帯電話の通信速度は9600bpsとかでしたから、こちらも通信速度は重視されませんでした。つまり、BluetoothはWi-fiのように通信速度を最大限求める技術ではなく、機器と機器を簡単に接続するために生まれてきた技術なのです。言い換えれば、Bluetoothは接続性を重視した技術であるのです。
接続性と言えば、簡単に接続できることも重要ですが、それと同じぐらい安定して接続できるということが求められます。Bluetoothでは、安定した接続のために周波数ホッピングという技術を使っています。そこで、Bluetoothがなぜ周波数ホッピングを使っているのかを説明する前に、まず周波数ホッピングがどのような動きをしているのかを説明します。
通常の無線通信は、周波数、すなわちチャンネルがきまっていて、そのチャンネルで通信をし続けます。しかし、周波数ホッピングにおいては、下図の様に常にチャンネルをランダムに変化させながら通信します。しかも、かなり頻繁に周波数を変更します。Bluetoothではチャンネルが1秒間に1900回も変化するというのだから驚きです。

周波数ホッピングのイメージ
それでは、なぜBluetoothは周波数ホッピングを使っているのでしょうか?それはBluetoothが2.4GHzという「どんなシステムでも使って良い周波数」を使っていることに由来します。
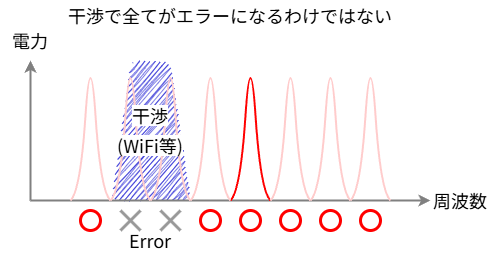
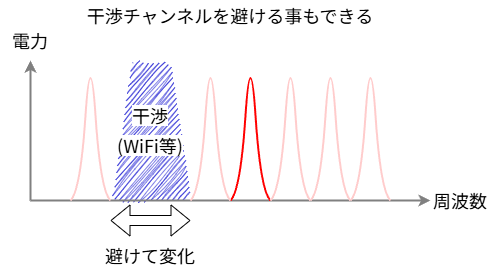
2.4GHzについてはもはや詳しい説明は不要でしょう。Wi-Fi、コードレス電話、ドローンと数えられないほどの機器が使っている周波数です。ですから、2.4GHzは全周波数の中でも最も混雑している周波数である、と言って良いでしょう。Bluetoothもそこで通信する以上、だれがどんな電波を出しても文句は言えないという周波数の状況下で通信する必要があるというのが前提となります。それを踏まえて、Bluetoothが周波数ホッピングを使い、チャンネルを頻繁に変化させる理由一つは、他のシステムからの干渉を素早く回避するためだと言えるでしょう。
もしも、ある通信がずっと同じチャンネルを固定で使っていたとして、そのチャンネルが他の電波による干渉によって使えなくなった場合、通信が維持できなくなり回線が切れる可能性があります。システムによっては、回線が維持できなくなってから、使用チャンネルを変えるというものもありますが、それだと一定時間接続が切れている時間が発生してしまいます。しかし、Bluetoothのようにチャンネルが常に変化している周波数ホッピングであれば、干渉が発生しても、そのチャンネルのみ短時間通信できないだけなので、エラーこそ発生しますが回線が途切れることはありません。つまり、周波数ホッピングという方式は、電波干渉があった場合に、その影響でエラー率が上がる可能性はあるが、その代わり通信が切断する可能性は低くなるようにできているのです。また、特定チャンネルでエラーが連続する場合は、そのチャンネルを使わないようにすれば良いので、ずっとエラー率が高いということもありません。
周波数ホッピングを使う二つ目の理由は、Bluetooth自体が、誰にも管理できないということです。例えば、同じ周波数を使うWi-Fiと比較してみましょう。Wi-Fiも沢山の機器がそれぞれ勝手に通信するというイメージがあります。しかし、その通信をよく見てみると、通常は1つのアクセスポイント(AP)に、複数の子機が接続するという「1対N」の通信です。一つのAPが接続する子機を管理するため、各子機は周波数や送信タイミングなどAPの指示に従いながら通信を行います。そのため、Wi-Fiにおいては、干渉を減らすように一応ある程度の秩序が守られて通信は行われていると言えます。一方、Bluetoothは「1対1の通信が沢山ある」というイメージです。電車内をイメージしてみてください。皆さんのスマホとイヤホンは1対1で接続されていますが、隣で立っているお兄さんのスマホとイヤホンもやはり1対1で接続されています。しかし、皆さんのスマホと隣のお兄さんのスマホ、そして更に隣のお姉さんスマホに至るまで、皆さんそれぞれがBluetoothを使っているのにもかかわらず、それぞれが何の連携も取っていません。となると、Bluetooth機器同士どうやって干渉しないようにお互いのチャンネルや時間を割り当てるのか?できませんよね?だったら、チャンネルは最初から割り当てない、各端末が好き勝手に通信した方が良い、それがBluetoothの考え方です。
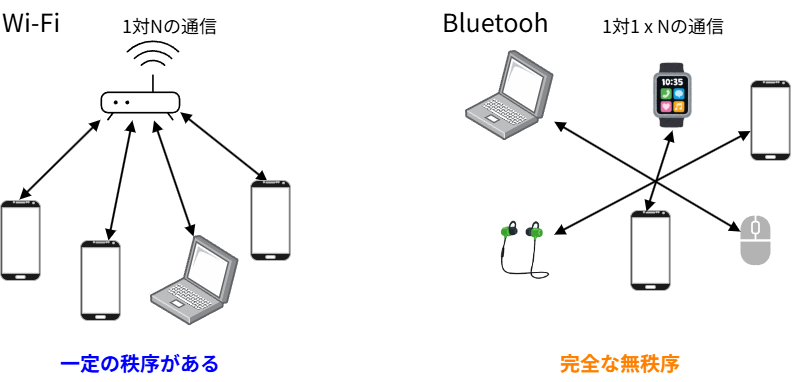
WiFiとBluetoothの違い
各端末がばばばっと高速にチャンネルを変えているなかで、お互いのチャンネルが一致(衝突)しなければ通信できる、運悪くチャンネルが衝突してしまったら、その時は通信できない。でも、それぐらいは仕方がない、そんな考え方が周波数ホッピングの基本です。ちなみに、Bluetoothには79チャンネルありますので、2台(組)のチャンネルが衝突する確率は約1.2%ぐらい、3台なら3.8%ぐらいになります。これは、仮にBluetooth以外の干渉が全く無かったとしても、常に数パーセントのエラーが出てしまうという意味でもありますが、Bluetoothではその程度のエラー率は許容できるように設計されているので、回線の切断はされません。もし、Bluetoothがチャンネル固定で2台の機器が通信するとしたら、98.8%のケースでエラーなく通信できますが、運悪く1.2%を引いてしまうと、その時は通信が切断されるということになります。つまり、周波数ホッピングというのは、無秩序な状況下において、多少のエラー率を犠牲にしても、回線の切断を防いでくれる技術なのです。
また、周波数ホッピングには回線の切断を防ぐという以外にも、(OFDMのような他の拡散技術と比べて)帯域を広く使う割に回路は簡単で電力消費量が少ない、周波数が一定ではないため傍受しにくい、等のメリットもあります。
まとめますと、Bluetoothは周波数ホッピングを使うことで、干渉が多く、かつ無秩序の状態である2.4GHzの周波数においても、省電力でありながら、安定して通信ができるように設計されている、ということになります。
Bluetooth Low Energy
Bluetoothは、もともとマウスやキーボード、携帯電話のヘッドセット(通話をするためのイヤホンとマイクのセット)などでの使用が想定されていましたが、Bluetoothのバージョンが上がる度に、どんどんと用途は増えていきました。例えば、ヘッドホンをはじめとする体に付ける機器、すなわちウエアラブルな機器との無線通信は、”結果的に”Bluetoothがスタンダードとなりました。ウエアラブルな機器は小型化が求められます。そして、機器がどんどん小型化していくと、バッテリーも小さくなってしまうわけで、更なる省電力化が求められました。また、IoT機器などもにもBluetoothが使われることが多くなりましたが、それら機器は電池が交換式だったり、頻繁に充電できないという構造のものが多く、こちらも消費電力が問題視されました。このように、設計当初は低かったはずのBluetoothの消費電力は、徐々に重荷になりつつあったのでした。
そこで、このブログでは頻出なフィンランドのノキアを中心として、これまでよりもさらに消費電力を低くした、Bluetooth Low Energy、略してBLE※2が開発されました。BLEはBluetoothの追加機能であり、Bluetoothのversion4.0で追加されたとなっています。しかし、BLEは従来のBluetoothと異なる部分が多く、物理的な互換性が全くありません。そのため、単なるバージョンアップとは考えられておらず、従来のBluetoothとBLEは全く別のものと捉えるのが正しいです。周波数は変わっていないのでアンテナこそ共用できるものの、両者の内部回路は全く別に作られています。そのため、従来のBluetoothはClassicと名付けられ、BLEとは分けて考えられるようになってしまいました。
そんな、BLEではありますが、2.4GHzという周波数と、周波数ホッピングを行うという点についてはClassicと同じであり、そのため無線的な特長はClassicのものを引き継ぎついでいます。干渉に強いのも、無秩序に強いのも、BLEでも変わりはありません。じゃあ、BLEとClassicと何が違うのでしょうか?
BLEは後発ですので、様々な改良が加えられました。例えば、アドバタイズというチャンネル。子機が自分の存在を知らせるために定期的に電波を発信する、いわゆる「ビーコン」の動きができるようになりました。しかも、このチャンネルは無線LANが使わないちょうど「隙間」のところを使う様になっていて、2.4GHzとしては安定して電波の存在が確認できるようになっています。この技術は、最初BLEビーコンとして使われ、今はAppleのAirTagなどでも使われています。

Bluetooth LEビーコン
アドバタイズチャンネルを含めて、ClassicからのBLEの変化を簡単にまとめます。
- 1チャンネル当たりの帯域幅が1MHzから2MHzになった
- 全チャンネル数が79から40に減った
- 最大通信速度は下がった(ただし、今後のバージョンで速度を上げる予定)
- チャンネルホッピング周期が遅くなった
- Classicではホッピング周期固定だったが、BLEは極力ホッピングを減らす動作をする
- パケットサイズが小さくなった
- 通信速度は落ちるが、遅延は小さく出来る
- アドバタイズチャンネルができた
- ビーコン的な動作が可能となった
- 機器のスキャンは、アドバタイズチャンネルのみをモニターすれば良なった
BLEの最大の特長は、何と言ってもその名の通りの省電力であることです。機器にもよりますが、BLEの消費電力はClassic機器の1/10以下になるともいわれています。上で挙げた主な変化も、多くが電力消費量削減を目的としています。例えば、「チャンネル当たりの帯域幅が広がった」となっています。これにより最大通信速度が上げられるのですが、BLEではそれを通信速度に使わず、通信時間を減らす方向に使っています。「パケットサイズを小さくした」のも、遅延を小さくするのもありますが、最小通信時間を小さくして送信機をOFFする時間を延ばす(デューティ比を減らす)ことが出来るからです。このように、BLEはClassicの仕組みを根本から変えたわけではありませんが、小さな工夫を重ねた結果、Classicよりもかなり省電力になっているようです。もちろん、消費電力を下げるとデメリットも出てきます。BLEはマウスとかセンサー、スマートウォッチのように間欠通信する場合にはは効果があるものの、オーディオ伝送のようなずっと連続している通信には向いていませんでした。
プロファイル
Classic、BLE共にBluetoothの機能は、「プロファイル」と呼ばれるもので実現されます。しかし、このプロファイルこそがBluetoothのわかりにくさを象徴する存在となっています・・・ 逆に言うと、Bluetoothを理解するためには、プロファイルの説明が外せないんですよね。
Bluetoothによるマウス、電話、ヘッドホン、これらはすべてプロファイルによって実現される機能です。プロファイルは一種の”接続アプリケーション”だと考えられます。親機、子機両方に同じプロファイルがインストールされていれば、その通信機能が使えるようになる、そういうものです。例えば、「Bluetoothでマウスやキーボード用の通信をしたい」となった場合、HID (Human Interface Device Profile)と呼ばれるプロファイルを使います。当然、子機であるキーボードやマウスがHIDに対応している必要があるのですが、それと同時に親機であるPCやスマホ側もHIDに対応している必要があります。逆に言えば、HIDがインストールされていない親機では、HIDに対応したキーボードやマウスは使えないことになります。
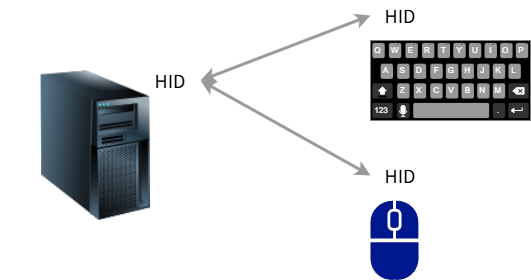
プロファイルは親も子も必要
ちなみに、この後出てきますが、プロファイル名は正式名称の頭文字を取った略語が付けられることになっています。しかし、略した後の文字数が3文字だったり5文字だったり、プロファイルの"P"が名称に入れられたり、入れられなかったりと命名ルールが曖昧で、それもプロファイルを分かりにくくしている一因になっていたりします。
次に、バージョンの話です。各プロファイルにバージョンがあるのですが、プロファイルとは別に、Bluetoothのバージョンというものもあります。例えば最新のiPhone16eはBluetooth5.3搭載となっていますが、これはBluetoothのバージョン5.3に対応していることを表します。しかし、そのことはBluetoothバージョン5.3が対応する全てのプロファイルを搭載している、という意味ではありません。ハードウエア的にバージョン5.3までにリリースされたプロファイルに対応可能であるという意味です。例えば、iPhone16e(iOS18)が対応しているプロファイルは、Apple公式HPによると以下の通りとなっています。
| プロファイル名 | 正式名称 | バージョン | 概要 |
|---|---|---|---|
| HFP | Hands-Free Profile | 1.8 | ヘッドセットや、カーナビ等と接続してハンズフリー通話が行える |
| PBAP | Phone Book Access Profile | 1.2 | カーナビ、カーオーディオから、スマホ内の電話帳の連絡先にアクセスできる |
| A2DP | Advanced Audio Distribution Profile | 1.4 | 高音質のオーディオが楽しめる |
| AVRCP | Audio/Video Remote Control Profile | 1.6 | スマホの音楽・動画再生を別の機器から制御できる |
| PAN | Personal Area Network Profile | 1.0** | Bluetoothでインターネット共有する |
| HID* | Human Interface Device Profile | 1.0** | マウス、キーボード、ゲームパッドと接続できる *公式HPには記載は無いが、HIDのBLE版であるHOGPプロファイルも接続可能な模様 |
| MAP | Message Access Profile | 1.4 | カーナビ等で、スマホのメッセージ通知、閲覧ができる |
| WiAP | Wireless iPhone Accessory Protocol | - | iPhone専用周辺機器用のプロファイル (カスタムプロファイル) |
** Apple公式サイトにはバージョンの記載は無いが、1.0対応と思われる
iPhone16eのBluetoothのバージョンは5.3ですが、それに加えて各プロファイルにもバージョンが付いています。例えば、A2DPはバージョン1.4対応となっています。これは、Bluetooth5.0に合わせて改版されたバージョンで、A2DPとしては最新バージョンです。ですから、A2DP1.4は、Bluetooth5.0以上でないと動きません。しかし、iPhone16eがA2DP1.4対応ということと、iPhone16eのBluetoothが5.3ということは、厳密には関係ありません。Bluetooth5.3は、A2DP1.4が動かせることを意味しますが、Bluetooth5.3の機器にA2DP1.4を載せるかどうかは、メーカーが決定します。今回はAppleがA2DP1.4を載せた、というだけで、Bluetooth5.3だけどA2DPは1.3までしか対応しないということも可能です。もちろん、最新のバージョンに対応しているのに、古いプロファイルを載せる意味はありませんので、通常は可能な限り最新のプロファイルだとは思いますが・・・ それにしてもややこしいですね。
さて、Bluetooth5.3で対応しているプロファイルはもっと沢山ありますが、公式にはiPhone16eはこれ以外のプロファイルに対応していないということになります。iPhoneには対応していないが有名なものでは、OPP(Object Push Profile)というプロファイルがあります。これは、電話帳やスケジュールを転送するためのプロファイルで、Androidでは多くのスマホが対応していますが、iPhoneは対応していません。どのプロファイルに対応するかはスマホメーカーが決めることですが、OSとしてAndroidがサポートしているプロファイルは、iPhoneに比べるとずっと多いです。むしろ、iPhone(およびiPad)は対応するプロファイルが少ない方の機器と言えるかもしれません。逆に、対応プロファイルが多いのはWindows搭載のノートPCで、大概のプロファイルに対応しています。いずれにしても、各プロファイルに対応するかどうかは機器メーカーが決めることであり、ユーザーでプロファイルを追加、変更することは出来ません。
ただし、メーカーによるOSやファームウエアのバージョンアップにより、対応プロファイルが増えることはあります。例えば、日本で最初のiPhoneであるiPhone3Gは、発売当初A2DP/AVRCPに対応しておらず、iPhoneとBluetoothヘッドホンを接続することが出来ませんでした。しかし、発売から1年経った後、OSのアップデートと共にA2DPに対応するようになりました。このように、プロファイルはソフトウエアなので、ハードウエアさえ対応していれば、後から追加(場合によっては削除)されることもあります。
ともかく、Bluetoothにはプロファイルという機能を表す概念と、基となる機能であるBluetoothのバージョンという2つの概念があり、これらが直接にはつながっていない上に、大概のメーカーは何の説明もしないため、ユーザーの混乱を招く原因となっています。
次回予告
Bluetooth LE Audioってなに?の”その1”は、BluetoothやBLEの仕組みを説明しました。次回”その2"では、Bluetooth Classcのオーディオについての話をしたいと思います。
それでは、次回もお楽しみに!
※1; スマートフォン等で使われている、AirDrop(Apple)やQuick Share(Google)では、Bluetoothと無線LANの両方を使って、機器間ファイル伝送を実現している。Bluetoothがファイル伝送に使われることもあるが、主な役割は相手機器の検出、接続である。
※2; あるいはBluetooth LEと略されることも多い。